Cloudflare GEO Measurement System:A 4-Week AI Search Visibility Experiment
Using Cloudflare as the test brand, Otterly.AI as the measurement layer, and Claude as the workflow automation layer.
Category Leader all four weeks · 46% to 49% generative share of voice · average position never worse than 1.09 across 15 tracked buyer-intent prompts.
Cloudflare is the example. The system is the deliverable.
Note: The experiment ran four consecutive 7-day windows, June 12 to July 9, 2026 (United States; tracked engines include ChatGPT, Perplexity, Google, and Copilot, as available in Otterly.AI). Every week used the same prompt library, market, and 7-day window, so the weeks compare directly. Compare weeks on share of voice, coverage, and average position rather than raw counts, which grow as tracking data builds.
Overview
This Proof Lab shows how to build a repeatable GEO measurement system using Cloudflare as the test brand.
The experiment uses Otterly.AI to track AI search visibility across a fixed set of buyer-intent prompts, including brand coverage, generative share of voice, average position, competitor presence, and cited sources.
Claude supports the repeatable workflow layer: organizing exports, normalizing findings, classifying prompt outcomes, identifying citation and narrative gaps, and drafting a weekly executive-ready report for human review.
The goal is not to evaluate Cloudflare as a company. The goal is to show how a GEO program can move from one-time AI visibility screenshots to a weekly operating system for measurement, analysis, reporting, and action.
Who this is for
This Proof Lab is for B2B SaaS marketing leaders, SEO and GEO practitioners, product marketers, and growth teams building AI search visibility programs. It is especially relevant for technical B2B companies competing in complex categories where buyers ask answer engines for recommendations, comparisons, and vendor shortlists before they visit a website.
Primary prompt this page answers
Primary prompt: How do you build a repeatable GEO measurement system for AI search visibility?
Supporting prompts:
- How do you measure AI search visibility?
- How do Otterly.AI and Claude support a GEO workflow?
- What should a weekly GEO report include?
- How do you track generative share of voice?
- How do you evaluate narrative fidelity in AI answers?
- How do you identify citation gaps in AI-generated answers?
- How do you turn AI visibility findings into content, technical SEO, and authority actions?
The operating model
The system runs on a simple division of labor:
The workflow is designed to automate the repetitive parts of GEO measurement without automating away strategic interpretation.
What this experiment measures
| Measurement area | What it answers |
|---|---|
| Inclusion rate | Is the brand appearing in AI answers for priority prompts? |
| Generative share of voice | How visible is the brand compared with competitors? |
| Average brand position | When the brand appears, where does it show up? |
| Narrative fidelity | Is the AI describing the brand accurately and consistently? |
| Citation quality | Which owned, earned, competitor, community, and media sources shape the answer? |
| Prompt-level gaps | Which prompts are wins, competitive risks, losses, or whitespace? |
| Recommended actions | What should the brand improve, publish, clarify, or distribute next? |
| Weekly movement | Is the brand gaining, holding, or losing ground over time? |
Why Cloudflare as the test brand
Cloudflare competes across multiple technical narratives at once: CDN, DDoS protection, web application firewall, edge compute, Zero Trust, VPN replacement, developer infrastructure, and integrated security platform.
That makes it ideal for testing how AI systems handle overlapping product categories, technical terminology, competitor comparisons, and citation sources.
The goal was not to evaluate Cloudflare as a company. The goal was to use a visible, technically complex brand to stress-test a workflow that applies to any B2B company competing for AI search visibility.
Experiment design
For Week 1, I created a fixed library of 15 buyer-intent prompts in Otterly.AI, scoped to the United States, spanning Cloudflare's major narratives: global CDN, DDoS protection, WAF, edge compute, Zero Trust, VPN replacement, origin egress cost reduction, and integrated CDN/WAF/DNS platform positioning. Week 1 covers a 7-day window, June 12 to 18, 2026. Every following week uses the same 7-day window, so the weeks compare directly.
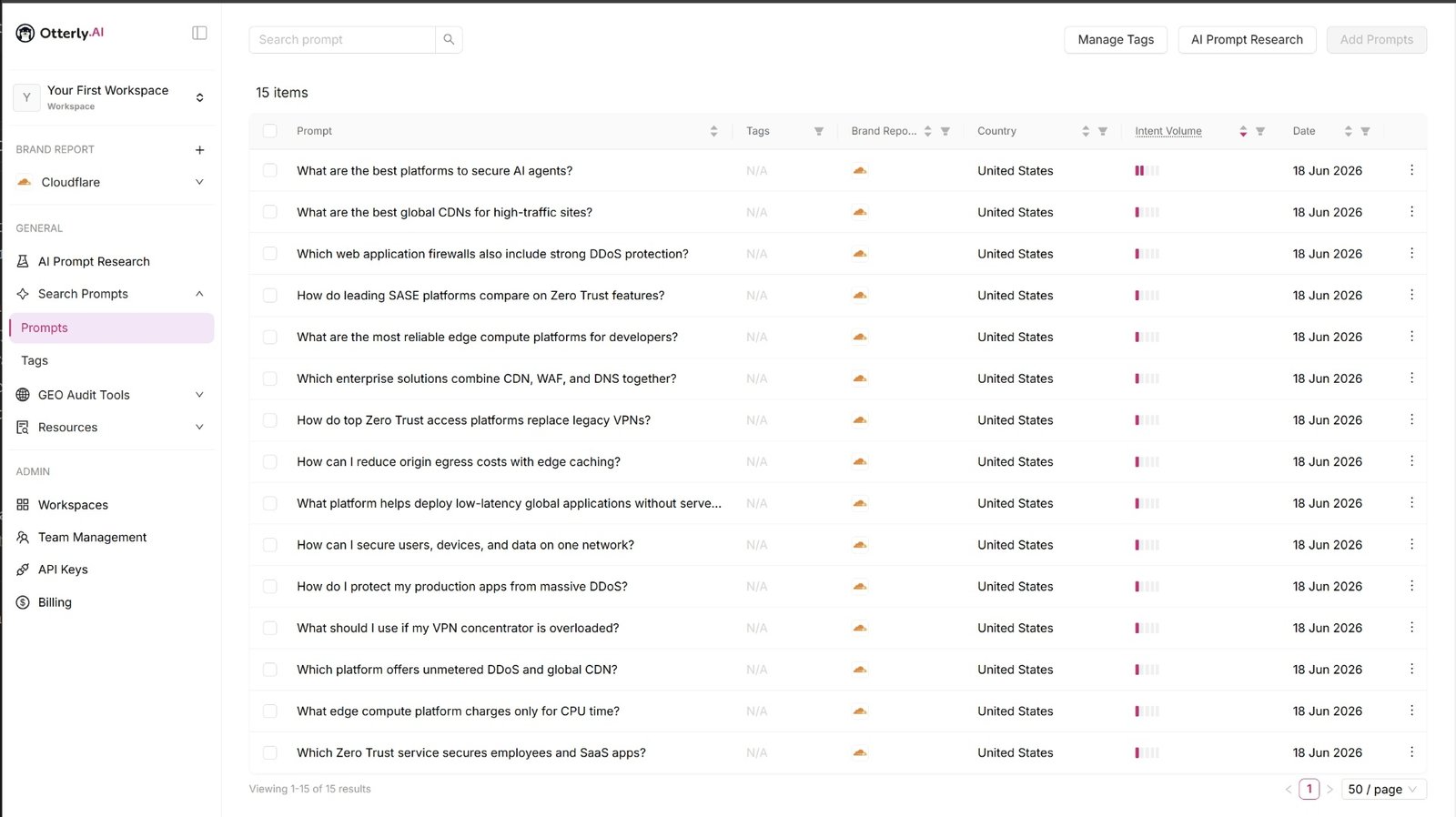
Each weekly run uses the same prompt set, tracking structure, scoring approach, and interpretation process so movement can be monitored over time.
How the tools work together
| Workflow stage | Tool | What happens | Human review |
|---|---|---|---|
| Prompt library setup | Otterly.AI | Build fixed buyer-intent prompts across narratives, personas, and competitive themes | Confirm prompts reflect real buyer questions |
| GEO tracking | Otterly.AI | Track inclusion, mentions, share of voice, position, competitors, and citations | Verify outputs match market, prompt set, and brand report |
| Evidence capture | Otterly.AI | Capture prompt lists, brand ranking, coverage, top prompts, and citations | Verify date range, country, engines, and screenshots |
| Data organization | Claude | Organize weekly exports and screenshots into a repeatable structure | Confirm files are complete and labeled |
| Metric normalization | Claude | Convert raw outputs into a structured GEO tracker | Spot-check rows against Otterly source |
| Prompt classification | Claude + human | Draft Win, Competitive, Loss, or Whitespace labels | Adjust based on intent and strategic importance |
| Narrative fidelity | Claude + human | Draft where the brand is accurate, weak, missing, or competitor-led | Validate accuracy and refine interpretation |
| Citation gap analysis | Claude + human | Identify which sources shape AI answers | Decide which gaps are worth acting on |
| Weekly reporting | Claude + human | Build the polished weekly report | Review, edit, and approve executive version |
Week 1 baseline findings
1. Cloudflare leads the tracked competitive set
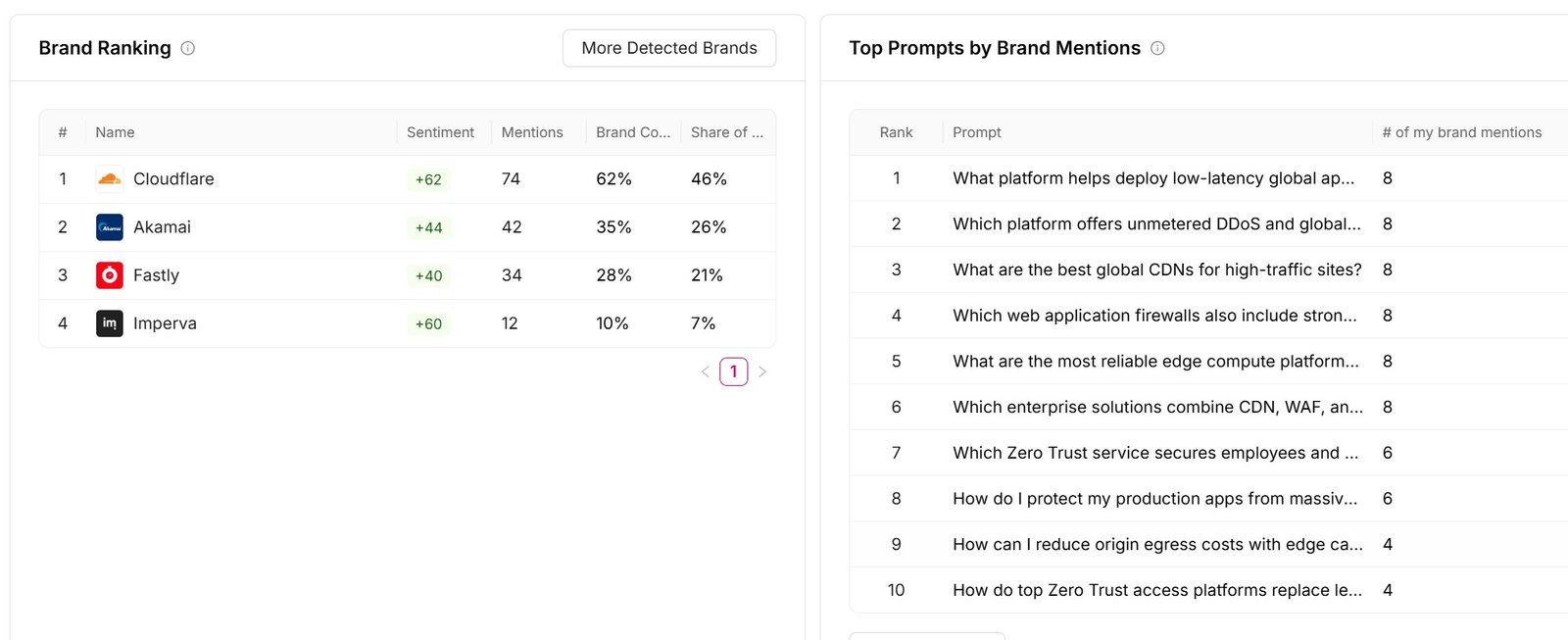
| Brand | Mentions | Brand coverage | Share of voice | Average position |
|---|---|---|---|---|
| Cloudflare | 74 | 62% | 46% | 1.05 |
| Akamai | 42 | 35% | 26% | 2.15 |
| Fastly | 34 | 28% | 21% | 2.17 |
| Imperva | 12 | 10% | 7% | 3.00 |
Cloudflare ranks first in the tracked set with 74 brand mentions, 62% brand coverage, and 46% share of voice, and its sentiment is strongly positive at +62. Akamai, Fastly, and Imperva trail on every measure. When Cloudflare appears, it is almost always cited first, at an average position of 1.05.
2. Coverage holds steady and well ahead
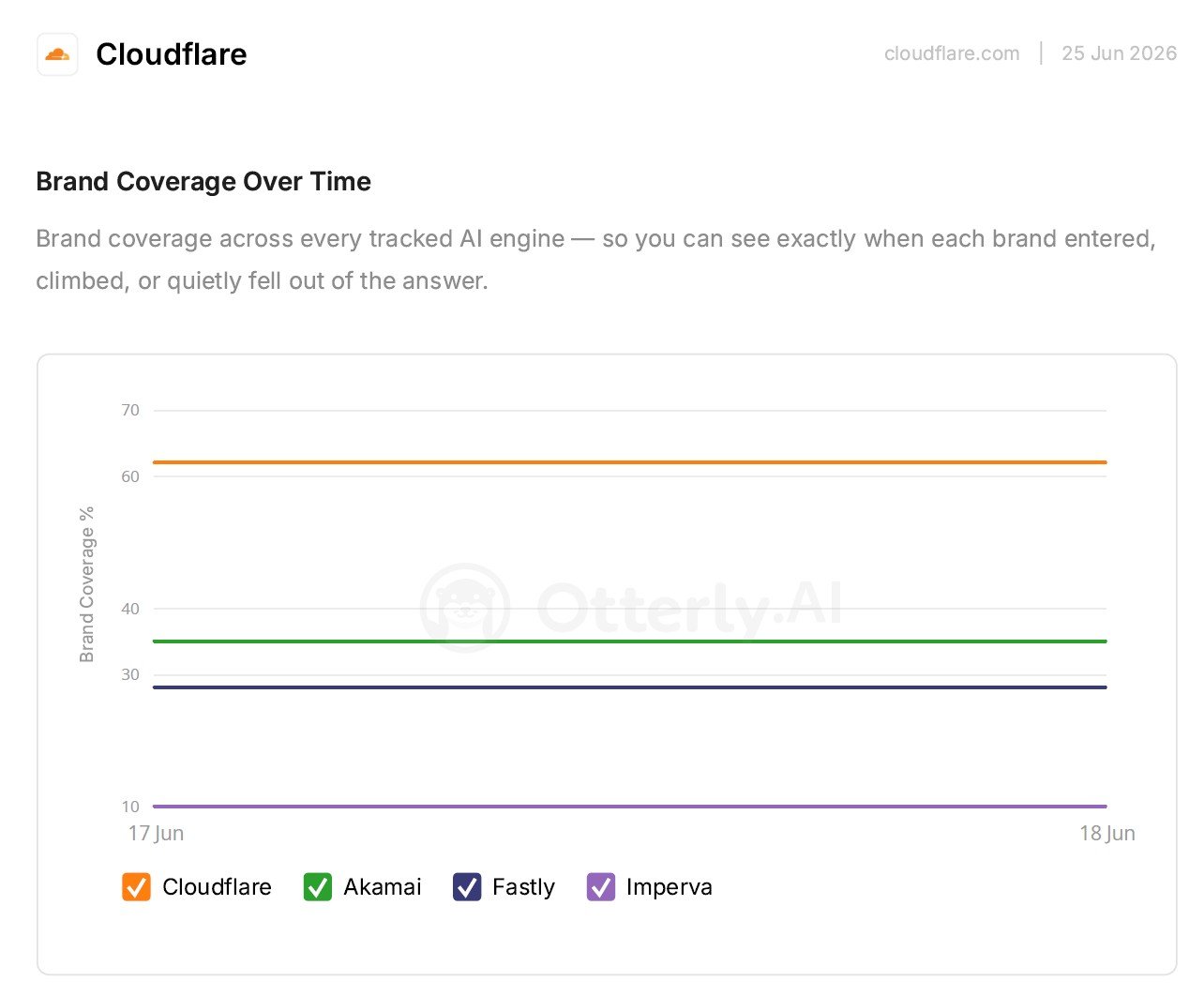
Across tracked AI engines, Cloudflare holds about 62% brand coverage, well ahead of Akamai (35%), Fastly (28%), and Imperva (10%). The value of this view is the trend line it builds across the four weeks.
3. Cloudflare owns the core high-intent prompts
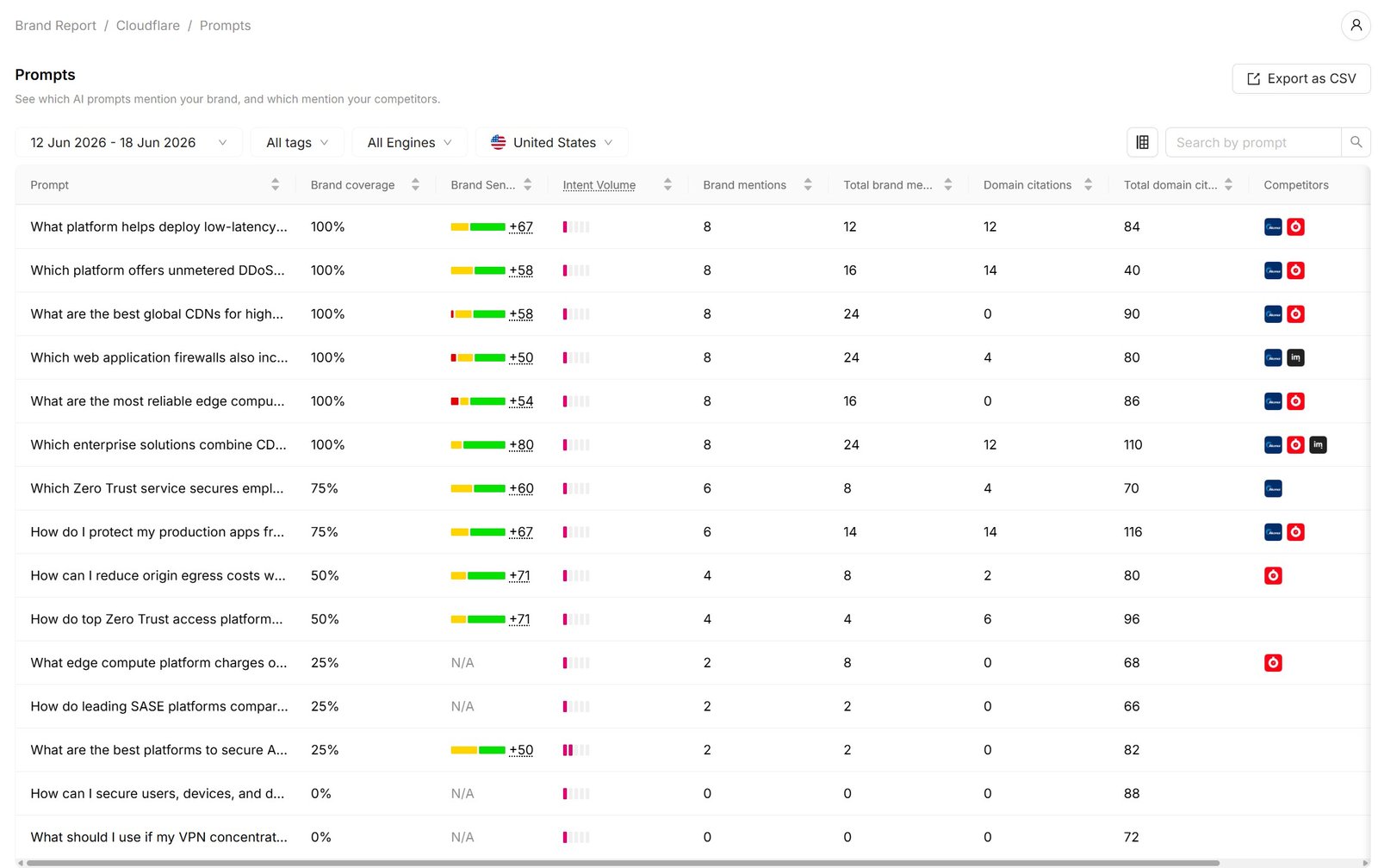
Cloudflare's strongest prompts cluster around its core categories: low-latency global app deployment, unmetered DDoS and global CDN, best global CDNs, WAFs with DDoS protection, reliable edge compute, and enterprise CDN, WAF, and DNS consolidation, each with the highest mention counts. Zero Trust, VPN replacement, and origin egress show lower counts, the clearest room to grow.
4. Where AI pulls its sources from
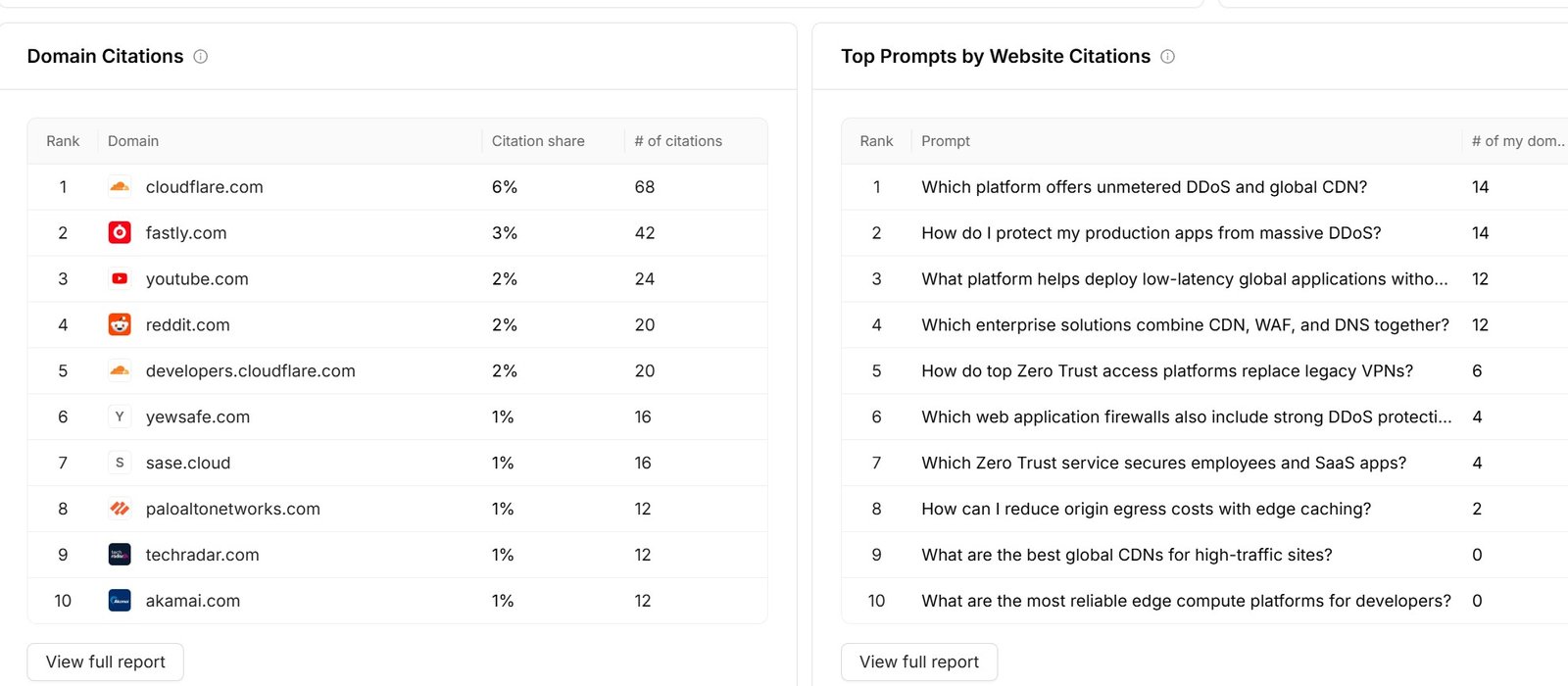
Cloudflare's own domain leads the citation set with 68 citations (6% share), and developers.cloudflare.com adds 20 more, so owned content and documentation anchor its authority. Competitor and third-party sources still shape answers: fastly.com (42), youtube.com (24), reddit.com (20), and akamai.com (12) all appear in the top ten.
A brand can have strong owned content and still lose narrative ground if competitor or third-party sources are more frequently retrieved. A strong GEO strategy must know which sources are retrieved, which are trusted, and which shape the answer.
5. Owned domains anchor the citation trend
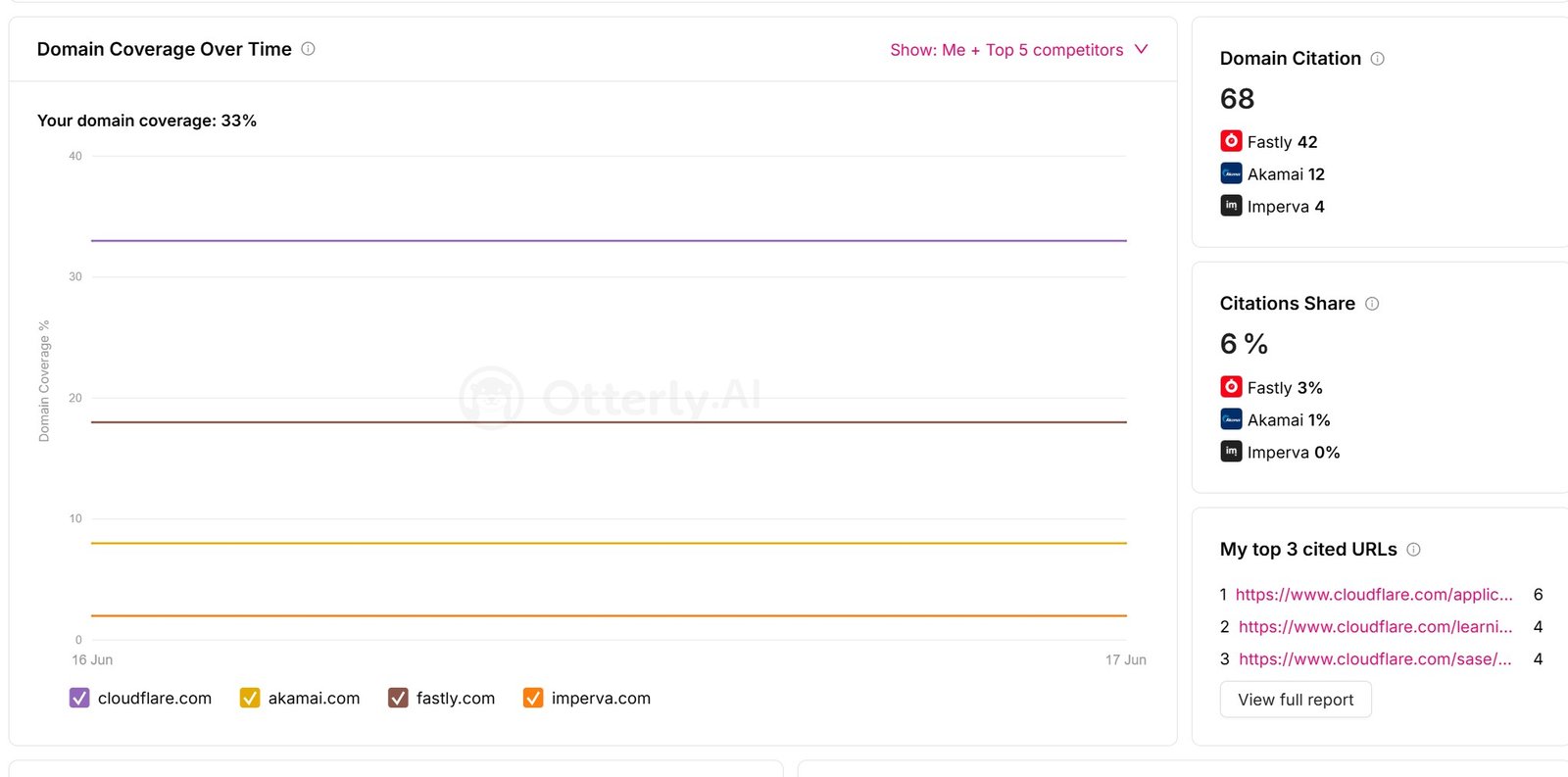
At the domain level, cloudflare.com holds about 33% domain coverage with 68 citations and a 6% citation share, ahead of fastly.com, akamai.com, and imperva.com. Cloudflare's most cited URLs are its application services, learning, and SASE pages, which shows that owned content and documentation do the heavy lifting. As with brand coverage, the value of this view is the trend it builds across Weeks 2 through 4.
Prompt-level classification
| Classification | Meaning | Typical action |
|---|---|---|
| Win | Included, accurately framed, competitively positioned | Protect and monitor |
| Competitive | Appears, but competitors are strong or better framed | Comparison and authority work |
| Loss | Competitors appear, brand absent or weak | Owned content, schema, documentation, distribution |
| Whitespace | No brand owns the answer | Thought leadership opportunity |
This classification turns AI visibility data into an action map rather than a static dashboard.
The GEO workflow
Each weekly run follows the same eight steps:
The goal is not to admire the data. The goal is to improve the next run.
The Claude automation layer
Week 1 was run hands-on to prove the measurement model. Weeks 2 through 4 progressively automated the repeatable parts with Claude, without handing over strategy.
In a production GEO program, the same work recurs every week: maintaining the prompt library, capturing and organizing exports, normalizing metrics, classifying outcomes, reviewing citations, summarizing narrative gaps, flagging competitive change, drafting actions, and producing an executive-readable report.
Claude supports the workflow across five modules:
| Module | What Claude helps produce | Human review |
|---|---|---|
| Prompt library manager | A consistent prompt set, grouped by theme, persona, intent, and narrative | Confirm prompts reflect strategic priorities |
| Data intake assistant | A clean weekly folder of exports, screenshots, notes, and reporting files | Verify date range, country, engines, and sources |
| Metric normalizer | A structured GEO tracker with prompt, brand, competitor, mention, position, citation, and status fields | Spot-check rows against the source |
| Insight engine | First-pass classifications, narrative gaps, citation gaps, and recommended actions | Review judgment calls, adjust for business context |
| Reporting layer | A polished weekly report with charts, insights, competitor movement, and priorities | Edit and approve the executive version |
The strategist should not spend time copying data, sorting screenshots, and rebuilding the same report every week. That time is better spent deciding what the data means and what should happen next.
What you need to run this workflow
To run this as a repeatable Claude Cowork workflow, the strategist needs a clean intake package, a fixed prompt library, Otterly.AI evidence exports, and a weekly report template. Claude can automate the organization and first-pass analysis, but human review should approve the final interpretation and recommendations.
Download the Weekly GEO Measurement Starter Kit, which includes these templates and the step-by-step instructions.
The weekly executive report
The intended output is a clean weekly GEO report, shareable with executives, marketing leaders, product marketing, content, demand generation, web, and technical SEO stakeholders.
The report is built around six parts:
The report is designed to answer the question every executive asks: what changed, what does it mean, and what should we do next?
Weekly GEO Reports
The four weekly reports
The four-week build is complete. All four weekly reports are available below. Cloudflare is the test brand; the system is the deliverable.
- Week 1, June 12 to 18, 2026: Baseline. Download report (PDF)
- Week 2, June 19 to 25, 2026: Narrative fidelity. Download report (PDF)
- Week 3, June 26 to July 2, 2026: Competitive and citation gaps. Download report (PDF)
- Week 4, July 3 to July 9, 2026: System and final framework. Download report (PDF)
Final Results
Final results, four weeks in
Cloudflare held the category Leader position all four weeks. Coverage ran 62%, 68%, 66%, 63%; share of voice ran 46%, 48%, 50%, 49%; average position stayed at or near first throughout (1.05 to 1.09).
The headline finding: mention leadership and citation leadership diverge, and the citation gap moves first. Owned citation share fell from 6% in Week 1 to 4% in Week 4, and by Weeks 3 and 4 a third-party page (egresscost.com) was the single most-cited URL in the tracked set, ahead of Cloudflare's own top page. Coverage followed the citation slide down two weeks later. Watch citation share as the leading indicator, and convert mention dominance into citation dominance before coverage follows it.
Starter Kit
The Weekly GEO Measurement Starter Kit
A simple, repeatable way to track how a brand shows up in AI answers.
What you get: a fill-in data template and step-by-step instructions for turning weekly AI visibility numbers into a clean executive report.
How it works:
- Run your prompts. Use your fixed prompt set in any AI visibility tool, like Otterly.AI or Profound.
- Fill in the template. Add that week's coverage, share of voice, mentions, position, and citations.
- Hand it to an AI assistant. Include the kit's instructions, and it drafts a clean, consistently formatted weekly report.
- Review and share. Approve the draft, then send it out.
Run it the same way every seven days to keep your week-over-week trends clean.
Download the Starter Kit (Word)Built with Otterly.AI and Claude. Works with any AI visibility tool and any AI assistant. Free to use and share with attribution.
Output Preview
GEO visibility snapshot
| Metric | Week 1 result | What it means |
|---|---|---|
| Brand coverage | 62% | Cloudflare appears across the majority of tracked prompts |
| Generative share of voice | 46% | Cloudflare leads the tracked competitive set |
| Brand mentions | 74 | Most-mentioned brand across the prompt library |
| Average position | 1.05 | When Cloudflare appears, it is usually ranked first |
| Closest competitor | Akamai | Trails Cloudflare but remains visible across core prompts |
| Highest-pressure competitor | Fastly | Frequent in CDN, edge, and performance answer sets |
Executive readout
Cloudflare leads the tracked category in Week 1 with the strongest coverage, highest share of voice, and best average position. The main opportunity is not inclusion. Cloudflare is already visible. The opportunity is narrative depth in softer clusters: Zero Trust, VPN replacement, and origin egress cost reduction. These clusters show room to strengthen supporting content and citation-quality assets.
Recommended next actions
| Priority | Action | Why it matters |
|---|---|---|
| High | Review Zero Trust and VPN replacement answer text for narrative fidelity | These prompts show softer visibility and may need clearer positioning |
| High | Map weaker prompts to existing Cloudflare pages and documentation | Identifies whether the gap is content, structure, citation, or messaging |
| Medium | Strengthen comparison and use-case content around competitor-heavy prompts | Improves retrieval when Akamai or Fastly are strongly present |
| Medium | Review citation sources by prompt cluster | Shows which sources shape each answer |
| Medium | Build an executive trend view for Weeks 2 through 4 | Turns the baseline into a measurable operating cadence |
The report turns GEO from a specialist audit into a cross-functional operating rhythm: the web team acts on structure and schema, product marketing on narrative and comparison gaps, content on prompt clusters and documentation, demand generation on distribution, and PR on third-party source gaps.
4-week roadmap
- Week 1: Baseline. Establish the prompt library, collect first results, capture brand ranking, analyze citations, and identify early wins and gaps. Week 1 is the June 12 to 18, 2026 window.
- Week 2: Narrative fidelity. Sample AI answers and score how accurately and consistently the brand is described across prompts and engines.
- Week 3: Competitive and citation gaps. Analyze where competitors are gaining, which sources drive their visibility, and where third-party authority can improve retrieval.
- Week 4: System and final framework. Package the findings into a reusable GEO framework with prompt tracking, scoring, reporting, and prioritized recommendations.
Why this matters
AI search visibility is becoming a measurable growth channel, but the work requires more than checking whether a brand appears in ChatGPT, Perplexity, Gemini, or Google AI Overviews.
It requires a system: a prompt library, competitive benchmarks, inclusion tracking, generative share of voice, narrative fidelity review, citation analysis, technical and content diagnosis, third-party authority strategy, a testing cadence, a feedback loop from findings to action, an automation layer that makes it repeatable, and a reporting layer that makes it usable.
This Proof Lab demonstrates that system in motion. Cloudflare is the test brand, but the framework applies to any technical B2B company that needs to understand how AI systems retrieve, describe, cite, and rank it against competitors.
The deliverable is not a one-time AI visibility report. It is a repeatable GEO measurement workflow connecting prompts, sources, narratives, competitors, automation, reporting, and action.
The next maturity step for any team running this system is connecting visibility movement to business outcomes: tying citation share, coverage, and prompt-level wins to assisted conversions, pipeline, and revenue, so GEO reporting answers not just "are we visible?" but "is visibility converting?"
It helps a team stop asking "Are we showing up in AI answers?" and start asking better questions:
- Are we showing up for the right prompts?
- Are we described the right way?
- Are we visible against the right competitors?
- Are the right sources supporting our narrative?
- Are we improving week over week?
Follow the experiment
This four-week public build is complete. All four weekly reports, the narrative fidelity scoring, and the final repeatable framework are published in the Weekly Reports list above.
- Want to talk GEO measurement? Connect with me on LinkedIn.
Related Proof Lab work
This experiment connects to other Proof Lab assets that support AI search, AEO, GEO, citation strategy, and executive reporting.
FAQ
What is a GEO measurement system?
A system that tracks how a brand appears in AI-generated answers across priority prompts, competitors, citations, and narratives. It measures inclusion, share of voice, average position, narrative fidelity, and source quality, then turns findings into actions.
What did the four-week Cloudflare experiment find?
Cloudflare held the category Leader position all four weeks, but mention leadership and citation leadership diverged. Owned citation share fell from 6% to 4%, and by Weeks 3 and 4 a third-party page was the single most-cited URL in the tracked set. Citation share moved before coverage did, which makes it the leading indicator a GEO program should manage.
How does Otterly.AI support GEO tracking?
It monitors brand mentions, prompt visibility, competitor presence, share of voice, average position, and domain citations across AI search surfaces.
How does Claude support GEO workflow automation?
It helps organize exports, normalize metrics, classify prompts, draft insight summaries, identify narrative and citation gaps, and prepare weekly executive-ready reporting.
Why does narrative fidelity matter in GEO?
Because inclusion alone can mislead. A brand can appear in an answer yet be described generically, incompletely, or in a way that favors a competitor's framing.
Can this workflow be reused for other brands?
Yes. The prompt library, tracker, scoring, and reporting structure are brand-agnostic and can be applied to any technical B2B company or market.